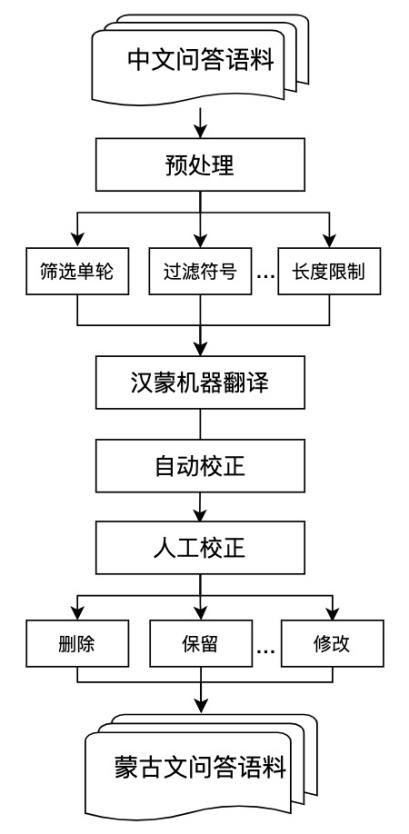
將預(yù)處理后的中文問答語料經(jīng)過本實驗室現(xiàn)有的漢蒙機器翻譯模型從中文翻譯成蒙古文。由于中文問答語料內(nèi)容存在一些噪聲,以及翻譯后的蒙古文譯文中有語序錯誤和錯別字等問題,最后,我們對蒙古文語料進行校正。
本文對漢蒙機器翻譯過后的蒙古文問答語料內(nèi)容采用了自動校正和人工校對相結(jié)合的方法。自動校正是針對蒙古文語料中存在的編碼錯誤和名詞格附加成分使用不當(dāng)?shù)绕磳戝e誤,使用自動校對工具進行修正。
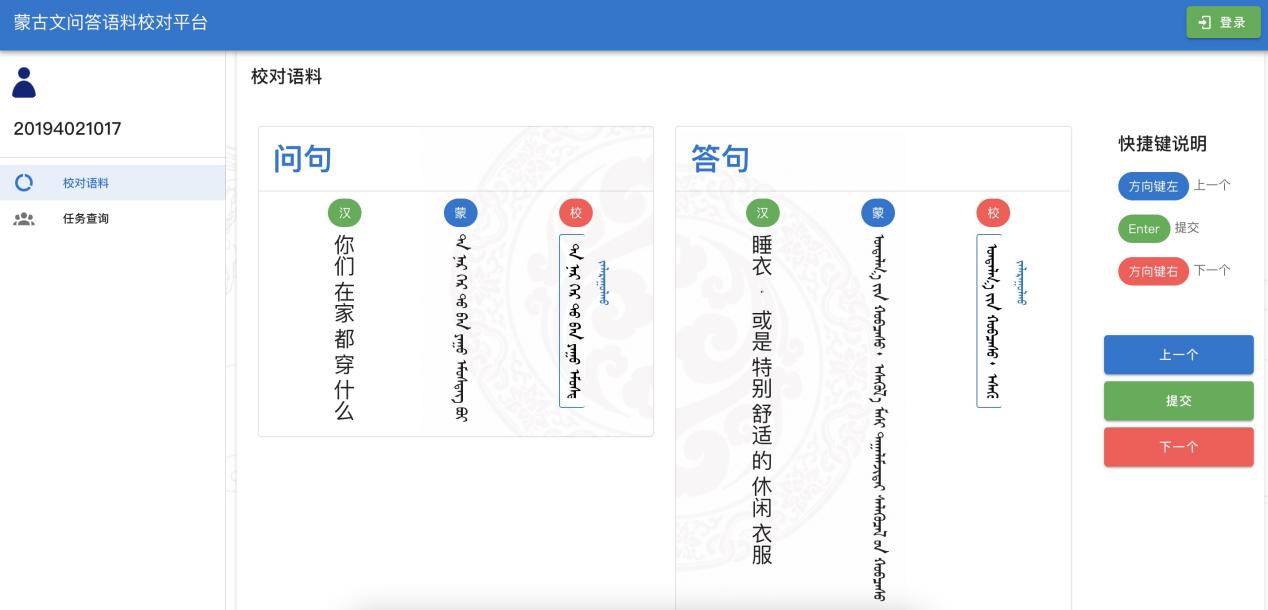
人工校正是一項費時費力的工作,同時,我們開發(fā)了一款語料管理及修改的平臺,該平臺支持多人在線校正雙語平行語料,并且可以自由地分配任務(wù),也支持實時監(jiān)督和統(tǒng)計任務(wù)進度,可以提高工作效率,平臺展示如圖2所示。
校正平臺將修改的內(nèi)容展示成四列,中文問答句為修改蒙古文問答句提供參考。通過平臺可以對語料進行一一校正,校正的主要工作內(nèi)容有:
(1)拋棄中文問題和答案不匹配、質(zhì)量較差、句子邏輯有誤的句子,相反保留質(zhì)量很好的蒙古文問答對,不需要其進行改動。
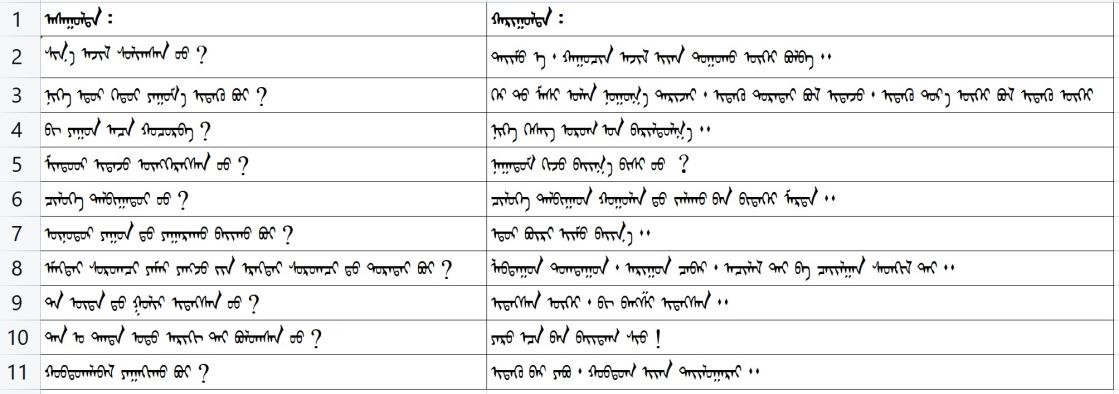
(2)對中文問答語料質(zhì)量較好,但翻譯后的蒙古文句子不通順、不完整情況進行補充修正,構(gòu)成符合蒙古文語法的句子。校正過程中遇到的部分典型例子如表3所示。
| 中文問句 | 中文答復(fù)句 | 蒙古文問句 | 蒙古文答復(fù)句 | 蒙古文問句(修改) | 蒙古文答復(fù)句(修改) |
| 你在干什么 | 打球 | 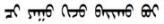 | 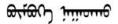 |  |  |
| 這飲料好喝嗎 | 不知道我沒喝 | 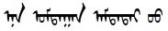 | 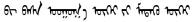 | 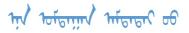 |  |
| 回新疆了? | 記得找我玩 | 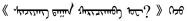 | 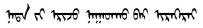 |  |  |
表中藍色字體表示保持原文,紅色字體表示對原文進行了修改。
第一行中,現(xiàn)在將來事態(tài)形動詞“
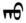
”“
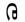
”,以該形動詞結(jié)尾的詞一般不能當(dāng)作句子結(jié)尾。所以應(yīng)當(dāng)根據(jù)問句的事態(tài)和人稱對句子進行修改,補充助動詞構(gòu)成完整正確的蒙古文句子。
第二行中,由于中文問答語料缺少停頓標(biāo)點符號,導(dǎo)致翻譯的蒙古文句子含義發(fā)生了變化。
第三行中,中文源句中的句子是祈使句或者感嘆句,導(dǎo)致翻譯后的蒙古文句子含有“《》”“
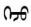
”、“
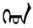
”等詞的情況。
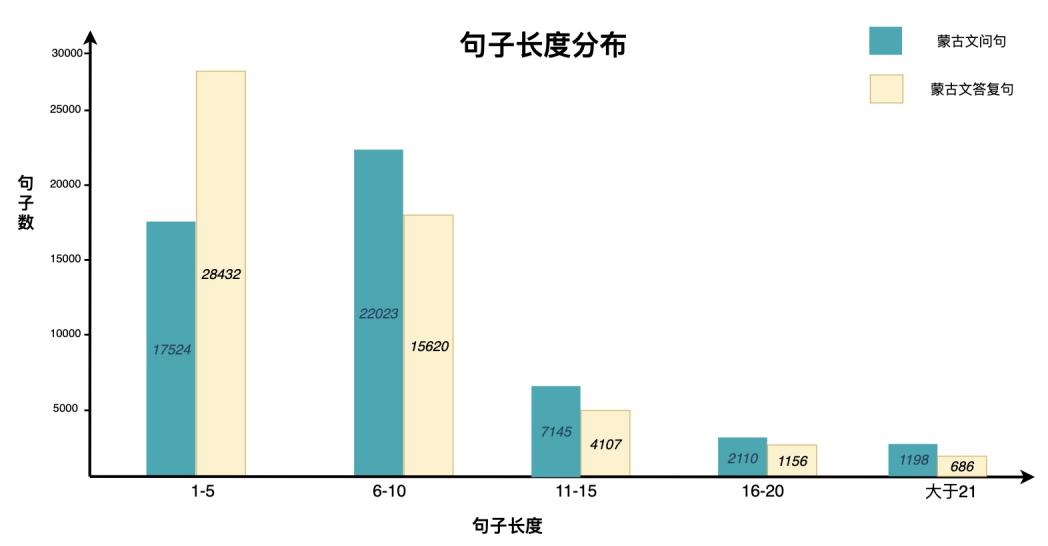
校正后的語料由問題和答案組成,屬于開放領(lǐng)域的單輪日常問答語料。


 ”譯為“為什么”、“
”譯為“為什么”、“ ”譯為“怎么”、“
”譯為“怎么”、“ ”譯為“什么”等。還有一些生活中交流的常用名詞,例如“
”譯為“什么”等。還有一些生活中交流的常用名詞,例如“ ”譯為“學(xué)校”、“
”譯為“學(xué)校”、“ ”譯為“朋友”、“
”譯為“朋友”、“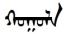 ”譯為“飯”等。說明符合日常對話邏輯。
”譯為“飯”等。說明符合日常對話邏輯。
