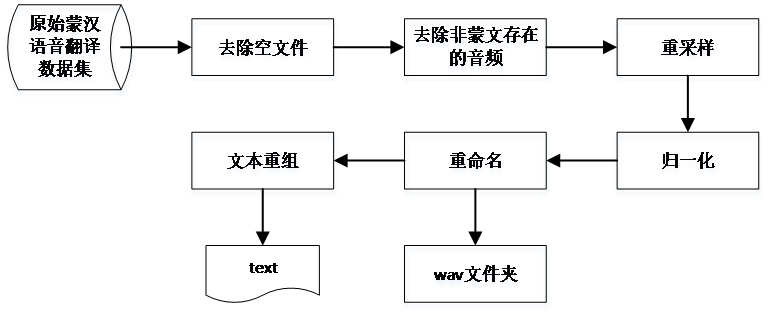
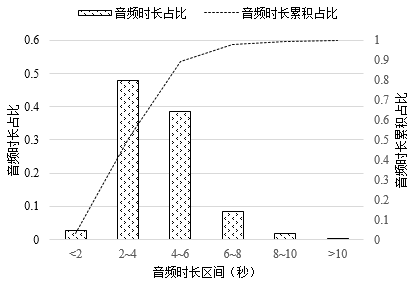
從36位錄音人員處收集數(shù)據(jù),數(shù)據(jù)的形式為每位說(shuō)話人一個(gè)單獨(dú)文件夾,文件夾內(nèi)為以句序號(hào)命名的wav文件及對(duì)應(yīng)的以句序號(hào)命名的蒙文和漢語(yǔ)文本。將此數(shù)據(jù)集稱為原始蒙漢語(yǔ)音翻譯數(shù)據(jù)集,對(duì)此數(shù)據(jù)集進(jìn)行預(yù)處理,經(jīng)過(guò)6個(gè)步驟后,可以得到最終的蒙語(yǔ)語(yǔ)音翻譯數(shù)據(jù)集。具體的預(yù)處理步驟如圖1所示。
圖1
?
數(shù)據(jù)的預(yù)處理過(guò)程 第一步,去除空文件。由于說(shuō)話人在錄制過(guò)程中,存在誤觸、錄制失敗等問(wèn)題,導(dǎo)致空語(yǔ)音文件的產(chǎn)生。因此,預(yù)處理首先要去除無(wú)語(yǔ)音數(shù)據(jù)的文件。方法為:設(shè)置一個(gè)閾值,當(dāng)語(yǔ)音音頻時(shí)長(zhǎng)小于閾值時(shí),認(rèn)為該文件內(nèi)不含有意義的語(yǔ)音數(shù)據(jù),因此將從數(shù)據(jù)集中刪除該音頻文件。在本數(shù)據(jù)集中,設(shè)置閾值為0.2秒。
第二步,去除非蒙語(yǔ)存在的音頻。在錄制的蒙文文本中,存在非蒙文詞,如2020、King、Uncle、Roger 等。由于數(shù)量較少,在預(yù)處理時(shí)簡(jiǎn)單地將這類(lèi)文本數(shù)據(jù)及對(duì)應(yīng)的語(yǔ)音數(shù)據(jù)從數(shù)據(jù)集中刪除。
第三步,重采樣。由于36位說(shuō)話人在不同的時(shí)間不同的設(shè)備上錄制語(yǔ)音,使得數(shù)據(jù)集中不同的音頻文件采樣率存在區(qū)別,如存在個(gè)別音頻的采樣率為44.1 kHz。為解決這一問(wèn)題,對(duì)所有音頻,重采樣至16 kHz。
第四步,歸一化。由于說(shuō)話人錄音時(shí)音量高低不一致,導(dǎo)致不同音頻信號(hào)間強(qiáng)弱差異較大。本文采用歸一化將語(yǔ)音數(shù)據(jù)歸于[-1,1]范圍內(nèi),即對(duì)每個(gè)音頻內(nèi)的值
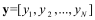
,計(jì)算幅度最大值

,則歸一化后的音頻信號(hào)為
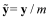
。
第五步,按照一定格式重命名音頻,具體格式描述如第2章所示。
第六步,文本文件重組。原始蒙漢語(yǔ)音翻譯數(shù)據(jù)集中每個(gè)音頻都對(duì)應(yīng)一個(gè)文本文件,不利于數(shù)據(jù)的處理。因此,將所有音頻的文本加入音頻名稱作為文本標(biāo)記,全部整合入一個(gè)文本中,形成最終的文本文件。